隨著企業數據規模的指數級增長和業務復雜度的提升,傳統集中式的數據架構逐漸暴露出瓶頸,如開發效率低下、數據治理困難、跨部門協作不暢等。為了應對這些挑戰,一種新興的架構范式——Data Mesh(數據網格)應運而生,它結合分布式領域驅動設計(DDD)的原則,為構建可擴展、敏捷且自治的數據處理服務提供了全新思路。本文將探討基于Data Mesh構建分布式領域驅動架構的最佳實踐,并聚焦于數據處理服務的核心要素和實施路徑。
一、Data Mesh與領域驅動設計的核心理念融合
Data Mesh由ThoughtWorks的Zhamak Dehghani提出,其核心思想是將數據視為一種產品,并通過去中心化的領域所有權來管理數據。這與領域驅動設計中的“限界上下文”(Bounded Context)和“領域模型”高度契合。在分布式架構中,每個業務領域團隊負責自己的數據處理服務,實現數據的自主管理和交付,從而打破數據孤島,提升整體效率。
最佳實踐建議:
- 識別領域邊界:基于業務功能劃分數據領域,例如用戶數據、訂單數據、庫存數據等,每個領域對應一個獨立的數據處理服務。
- 定義數據產品:將每個領域的數據封裝為可復用的產品,明確數據的所有者、消費者和質量標準,確保數據的一致性和可靠性。
二、構建分布式數據處理服務的關鍵組件
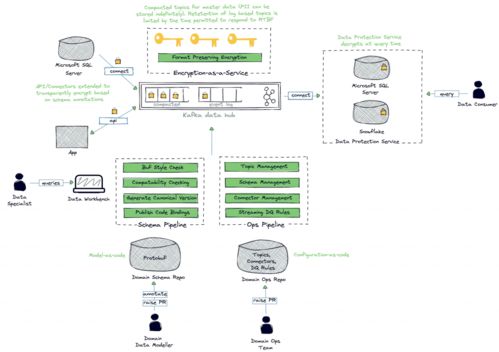
在Data Mesh架構中,數據處理服務是核心單元,它需要具備自治性、可發現性和互操作性。以下是最佳實踐中的關鍵組件設計:
- 領域專屬數據處理管道:每個領域團隊應構建自己的數據處理流水線,包括數據攝入、清洗、轉換和存儲。使用輕量級工具(如Apache Kafka、Airflow)實現流水線自動化,減少對中央團隊的依賴。
- 標準化接口與協議:通過API(如REST或GraphQL)暴露數據產品,確保跨領域的數據消費無需了解底層實現細節。采用通用數據格式(如Parquet、Avro)提升互操作性。
- 數據治理與質量監控:嵌入數據質量檢查、元數據管理和訪問控制機制。例如,使用數據目錄(如Amundsen)實現數據的可發現性,并利用自動化測試保障數據質量。
三、實施路徑與挑戰應對
從傳統架構遷移到Data Mesh需要循序漸進。最佳實踐建議分階段推進:
- 試點階段:選擇一個業務價值高、數據復雜度適中的領域作為試點,例如銷售數據分析服務。團隊需建立完整的數據產品生命周期,并驗證技術棧的可行性。
- 擴展階段:基于試點經驗,逐步推廣到其他領域。建立中心化的支持平臺,提供共享工具(如數據編排引擎)和治理框架,以平衡自治與標準化。
- 文化轉型:Data Mesh不僅是技術變革,更是組織文化的重塑。鼓勵團隊擁抱數據所有權,培養數據產品思維,并通過跨領域協作會議促進知識共享。
常見挑戰包括技術債務積累、團隊技能缺口和治理沖突。應對策略包括:投資自動化工具減少手動操作,提供培訓提升數據工程能力,以及設立輕量級治理委員會協調跨領域決策。
四、案例啟示與未來展望
以某電商平臺為例,通過實施Data Mesh,其訂單處理、用戶推薦和庫存管理等領域團隊獨立構建了數據處理服務。結果,數據交付時間縮短了60%,跨團隊協作效率顯著提升。隨著AI和實時計算技術的發展,Data Mesh架構有望進一步融合事件驅動設計,實現更動態的數據處理能力。
基于Data Mesh構建分布式領域驅動架構,通過將數據責任下放至領域團隊,能夠有效提升數據處理服務的敏捷性和可擴展性。企業應從理念認同、技術選型和組織調整三方面入手,以漸進式實踐邁向數據驅動的未來。